React 从 v16 开始启用了全新的架构,管理代号为 Fiber 。比起之前的实现极大地提高了性能,本文将会结合一个实例整体剖析一下 Fiber 的内部架构。
概览#
先来看一个例子 :
class ClickCounter extends React.Component {
constructor (props) {
super(props)
this.state = { count: 0 }
this.handleClick = this.handleClick.bind(this)
}
handleClick () {
this.setState(state => {
return {
count: state.count++
}
})
}
render () {
return [
<button key="1" onClick={this.handleClick}>Update counter</button>,
<span key="2">{this.state.count}</span>
]
}
}
当我们点击 Update counter 按钮以后,React 会做以下事情 :
- 更新
ClickCounter组件state的count属性。 - 检索并比较
ClickCounter组件的子组件及他们的props。 - 更新
span元素的props。
下面让我们深入来解析这个过程~
从 React 元素到 Fiber 节点#
React 每个组件渲染的 UI 都是通过 render 方法的,我们使用的 JSX 语法,会被编译成通过 React.createElemnet 方法来调用,比如上面的 UI 结构 :
<button key="1" onClick={this.onClick}>Update counter</button>
<span key="2">{this.state.count}</span>
会被转成下面的代码 :
React.createElement(
'button',
{
key: '1',
onClick: this.onClick
},
'Update counter'
),
React.createElement(
'span',
{
key: '2'
},
this.state.count
)
之后会产生如下的两种数据结构 :
[
{
$$typeof: Symbol(react.element),
type: 'button',
key: "1",
props: {
children: 'Update counter',
onClick: () => { ... }
}
},
{
$$typeof: Symbol(react.element),
type: 'span',
key: "2",
props: {
children: 0
}
}
]
简单解释一下上述的属性 :
$$typeof: 唯一地标识为React元素。type、key、props描述元素对应的属性。- 其它比如
ref属性暂不讨论。
ClickCounter 组件就没有任何 props 或者 key 了 :
{
$$typeof: Symbol(react.element),
key: null,
props: {},
ref: null,
type: ClickCounter
}
Fiber 节点#
在协调算法调用期间,每一个 render 转化的 React 元素都会被合并到 Fiber 节点树上,每个React 元素都有一个对应的 Fiber 节点, 不同于 React 元素,fibers 不会随着每个 render 而重新创建,它们是可变的数据结构。
不同类型的
React元素都有 **对应的 type** 来定义需要被做的工作。从这个角度,
Fiber可以被理解成一种展示需要做什么工作的数据结构,Fiber架构也提供了一种便利的方式来追踪、安排、暂停和停止工作。
当 Fiber 节点首次被创建之后,后续的更新 React 会复用 Fiber 节点并且只更新必要的属性。如果定义了 key ,React 还会选择是否仅单纯移动节点来优化性能。
转化完成以后我们就有了这样一个树结构 :

所有的 Fiber 节点都通过一个链表相连,并带有这三个属性 : child、sibling 和 return。(关于 Fiber 节点的设计后文会详细讲解)。
Current 和 workInProgress 树#
上面转化完成后的树就是 current 树,当React 开始更新时它会遍历 current 树,同时创建对应的节点组成了workInProgress 树,当所有的更新及相关操作完成后,React 会把 workInProgress 树的内容渲染到屏幕上,然后 workInProgress 树就变成了 current 树。
workInProgress树也被称为finishedWork树。
在源码中关键的一个函数就是 :
function updateHostComponent (current, workInProgress, renderExpirationTime) { ... }
副作用线性表#
除了常规的更新操作,React 还定义了 "副作用" 的操作 : 获取数据、订阅操作或是手动改变 DOM 结构,这些操作在 Fiber 节点中会被编码成 effectTag 字段。
ReactSideEffectTags.js 定义了在实例更新处理之后将会被做的操作 :
- 对于 DOM 组件:包含了新增、更新或移除元素的操作。
- 对于类组件:包含了更新 ref 和调用
componentDidMount、componentDidUpdate生命周期方法。 - ......
为了快速地处理更新, React 采用了很多高效的措施,其中一个就是建立 Fiber 节点的线性表,遍历线性表的速度快于遍历树。建立线性表的目的是标记带有 DOM 更新或其它副作用的节点,它是 finishedWork 树的子集,通过 nextEffect 属性相连。
举个例子:当我们的更新造成 c2 被插入到 DOM 中,同时 d2 和 c1 改变了属性值,b2 调用了一个生命周期方法,副作用线性表会将它们连在一起这样 React 之后可以直接跳过其它节点 :
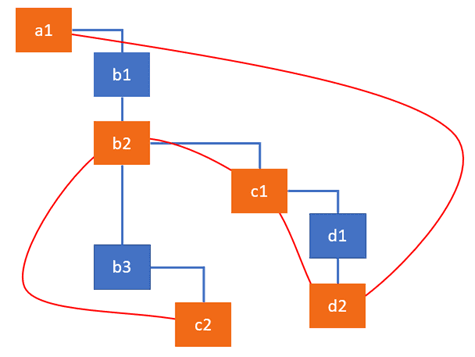
接下来让我们来深入 Fiber 执行的算法~
两个阶段#
React 在两个主要阶段执行工作 : render 和 commit 。
在 render 阶段,React 对通过 setState 和 React.render 计划的组件应用更新并找出需要更新到 UI 上的部分。如果是初始渲染,React 会创建一个新的 Fiber 节点,在之后的更新中会复用已经存在的 Fiber 节点来进行更新。这个阶段最终产生了标记有副作用的 Fiber 节点树。副作用描述了在接下来的 commit 阶段需要做什么。
render 阶段的工作可以被异步地处理。在这个阶段 React 可以依据(浏览器)空闲时间来处理一个或多个 Fiber 节点,然后停下来缓存已经完成的工作并响应一些事件,可以从暂停的地方继续处理,也可以根据需要废弃已经完成的部分从头再开始。这些可以出现是因为在这个阶段的处理不会导致任何用户可见的变化,比如说 DOM 更新。通俗地说,这个阶段是 可中断的。
在 render 阶段会调用一些生命周期方法 :
- [不安全] componentWillMount (已废弃)
- [不安全] componentWillReceiveProps (已废弃)
- getDerivedStateFromProps
- shouldComponentUpdate
- [不安全] componentWillUpdate (已废弃)
- render
从 v16.3 开始,一些遗留的生命周期方法已经被标记为 不安全,也就是官方已经不推荐使用的方法,它们将在未来的 v16.x 版本中启用警告,并将会在 v17.0 版本中删除,详细可阅读 Update on Async Rendering。
为什么官方会标记为不安全?因为 render 阶段不会产生像 DOM 更新这样的副作用,React 可以异步地更新处理组件,但是被标记为不安全的这些方法常常被开发者误用,往往会在这些方法中放入带有副作用的代码造成异步渲染出错。
相对地,commit 阶段总是同步的,因为这个阶段的处理会导致用户可见的变化,比如说 DOM 更新,因此 React 需要一次完成它们。
在 commit 阶段会调用这些生命周期方法 :
- getSnapshotBeforeUpdate
- componentDidMount
- componentDidUpdate
- componentWillUnmount
因为这些方法在同步的 commit 阶段被执行,所以它们可以包含带有副作用的代码。
render 阶段#
协调算法始终使用 renderRoot 函数从顶部的 HostRoot fiber 节点开始,但是它会跳过已经处理过的 fiber 节点直至遇到带有未完成工作的节点。比如,如果你在组件树深处中调用了 setState,React 将会从顶部开始快速略过父组件直到抵达了调用了 setState 方法的组件 。
工作循环的主要步骤#
所有 fiber 节点会在 工作循环 函数中处理,看一下循环中同步部分的实现 :
function workLoop (isYieldy) {
if (!isYieldy) {
while (nextUnitOfWork !== null) {
nextUnitOfWork = performUnitOfWork(nextUnitOfWork)
}
} else {
...
}
}
nextUnitOfWork 包含来自 workInProgress 树需要处理的节点的引用。当 React 遍历 Fiber 树时,它使用这个变量去获知是否还有其它未完成的 fiber 节点,处理完当前 fiber 节点后,这个变量会指向树中下一个 fiber 节点或是 null ,此时 React 会退出工作循环并准备提交更改。
当遍历 Fiber 树时有四个主要的函数被调用来初始化或者完成工作 :
这里有一个形象的动画来展示它们如何被使用,子节点将会被优先完成。
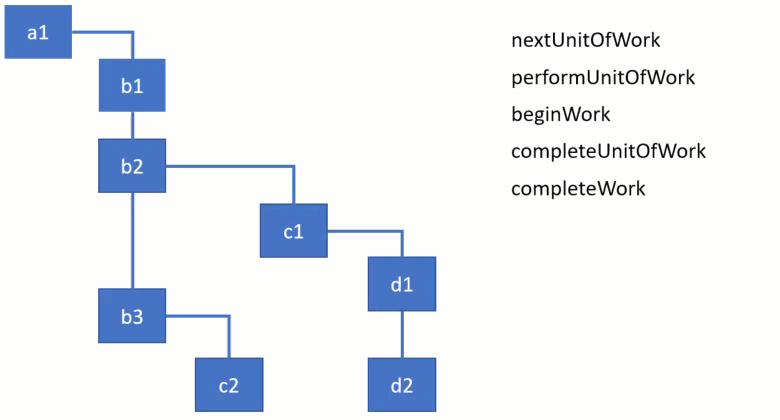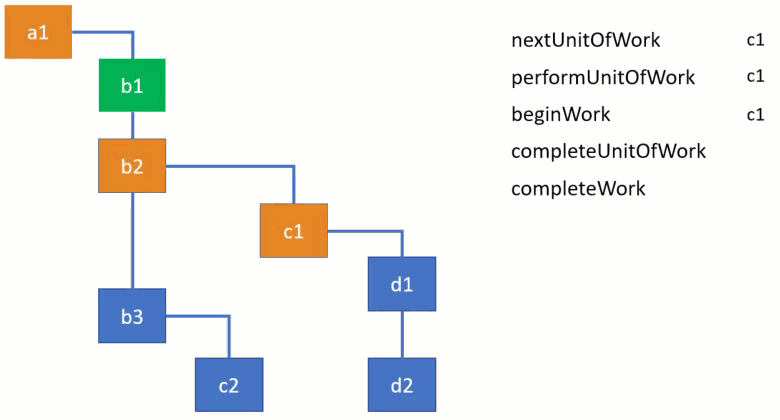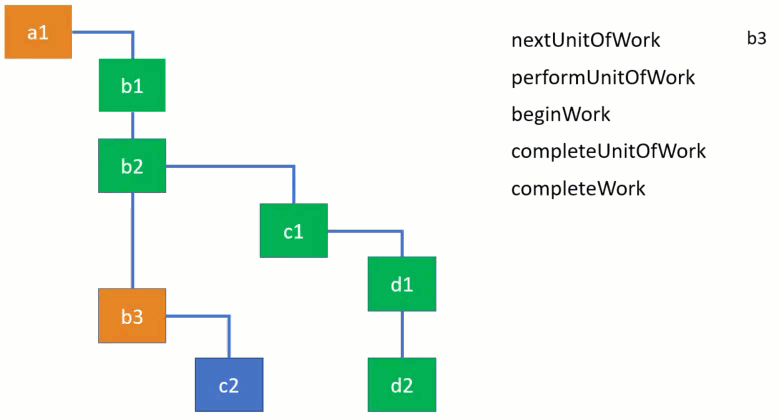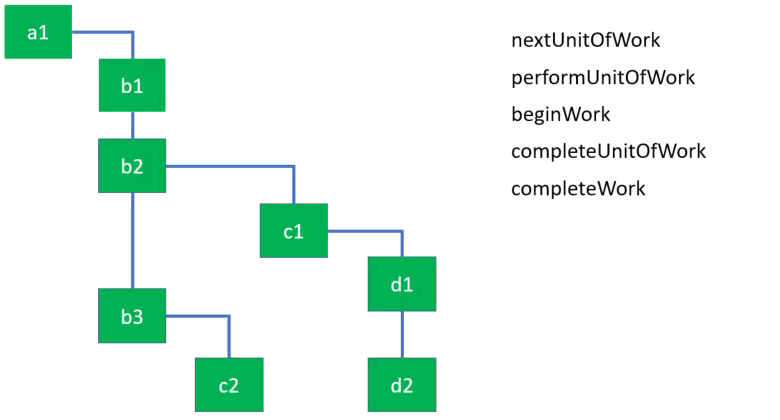
先看前两个函数 performUnitOfWork 和 beiginWork :
function performUnitOfWork (workInProgress) {
let next = beginWork(workInProgress)
if (next === null) {
next = completeUnitOfWork(workInProgress)
}
return next
}
function beginWork (workInProgress) {
console.log('work performed for ' + workInProgress.name)
return workInProgress.child
}
performUnitOfWork 函数接收一个来自 workInProgress 树的 fiber 节点然后通过调用 beginWork 函数开始工作,这个函数会执行一个 fiber 节点所有需要执行的操作(简化处理这里只打印了 fiber 节点的名字表示已完成)。beginWork 函数总是返回一个指向下一个子节点的指针或是 null。
如果有下一个子节点,它就会被赋值给 workLoop 函数中的变量 nextUnifOfWork,如果没有了,React 就知道已经到达这个节点分支的末尾,因此可以完成当前节点。一旦一个节点完成了,它将会处理兄弟节点的工作然后再回溯父节点。看一下 completeUnitOfWork 函数 :
function completeUnitOfWork (workInProgress) {
while (true) {
let returnFiber = workInProgress.return
let siblingFiber = workInProgress.sibling
nextUnitOfWork = completeWork(workInProgress)
if (siblingFiber !== null) {
return siblingFiber
} else if (returnFiber !== null) {
workInProgress = returnFiber
continue
} else {
return null
}
}
}
function completeWork (workInProgress) {
console.log('work completed for ' + workInProgress.name)
return null
}
Commit 阶段#
这个阶段从调用 completeRoot 函数开始。在这里 React 更新 DOM 并且调用可变的生命周期的方法。
在这个阶段 React 有 current 和 finishedWork(workInProgress)树以及副作用线性表。
副作用线性表会告诉我们哪个节点需要被插入、更新或删除,或者哪个组件需要调用它们的生命周期方法。这就是整个 commit 阶段会遍历处理的东西。
commit 阶段主要运行的函数是 commitRoot ,这个函数会做以下事情:
- 调用标记了
Snapshot副作用的节点的getSnapshotBeforeUpdate方法 - 调用标记了
Deletion副作用的节点的componentWillUnmount方法 - 执行所有 DOM 的插入、更新和删除操作
- 将
finishedWork树设为current - 调用标记了
Placement副作用的节点的componentDidMount方法 - 调用标记了
Update副作用的节点的componentDidUpdate方法
这有一个简化版的函数描述了上述过程 :
function commitRoot (root, finishedWork) {
commitBeforeMutationLifecycles()
commitAllHostEffects()
root.current = finishedWork
commitAllLifeCycles()
}
每一个子函数都实现了一个循环来遍历副作用线性表并检查副作用的类型来更新 :
-
commitBeforeMutationLifecycles: 遍历并检查节点是否有Snapshot副作用标记。function commitBeforeMutationLifecycles () { while (nextEffect !== null) { const effectTag = nextEffect.effectTag if (effectTag & Snapshot) { const current = nextEffect.alternate commitBeforeMutationLifeCycles(current, nextEffect) } nextEffect = nextEffect.nextEffect } } -
commitAllHostEffects: 执行 DOM 更新的地方,定义了节点需要做的操作并执行它。function commitAllHostEffects () { switch (primaryEffectTag) { case Placement: { commitPlacement(nextEffect) ... } case PlacementAndUpdate: { commitPlacement(nextEffect) commitWork(current, nextEffect) ... } case Update: { commitWork(current, nextEffect) ... } case Deletion: { commitDeletion(nextEffect) ... } } }有趣的是在
commitDeletion函数中React会调用componentWillUnmount方法。 -
commitAllLifecycles:React会调用剩余的生命周期方法componentDidMount和componentDidUpdate
现在我们已经了解了协调算法主要执行的过程,那我们把目光放在 Fiber 节点的设计上:整体通过一个链表相连,并带有 child、sibling 和 return 三个属性。为什么要这样设计?
设计原则#
我们已经知道 Fiber 架构有两个主要的阶段 : render 和 commit 。
在 render 阶段 React 会遍历整个组件树并执行一系列操作,这些操作都在 Fiber 内部执行,并且不同的元素类型会有不同的工作要处理,就像 Andrew 说的 :
当处理 UI 时,很大的一个问题是如果大量的工作同时执行,就会造成动画掉帧。
如果 React 采用同步的方式遍历整个组件树并且为每个组件处理工作,这很容易就会运行超过 16ms,进而就会造成视觉上的卡顿。但是我们完全没有必要采取同步的方式,React 的 设计原则 中有一些关键点 :
- 并不是所有的 UI 更新都需要立即生效(这样可能会掉帧)。
- 不同类型的更新有不同的优先级(动画响应远高于数据获取)。
- 一个基于推送的方案是由开发者决定如何调度;而一个基于拉取的方案则是由
React决定如何调度。
基于这些原则,我们所需要实现的架构就需要做到 :
- 暂停任务并且可以在之后恢复。
- 为不同的任务设置不同的优先级。
- 可以复用已经完成的任务。
- 可以终止不再需要的任务。
那什么东西可以帮助我们来实现这些?
新型的浏览器(和 React Native) 实现了可以帮助解决这个问题的 API : requestIdleCallback 。
这个全局函数可用于对在浏览器空闲期间调用的函数进行排队,简单看一下它的使用 :
requestIdleCallback((deadline) => {
console.log(deadline.timeRemaining(), deadline.didTimeout)
})
deadline.timeRemaining() 会显示有多少时间可以做任何工作,deadline.didTimeout 表示是否用完分配的所有时间。timeRemaining 会在浏览器完成某些工作后立即更改,所以必须不断检查。
requestIdleCallback实际上有些过于严格导致常常 不足以实现流畅的 UI 渲染 ,因此 React 团队不得不重新实现自己的版本。
React 这样调用 requestIdleCallback 来安排工作,将所有要执行的放入 performWork 函数中 :
requestIdleCallback((deadline) => {
while ((deadlne.timeRemaining() > 0 || deadline.didTimeout) && nextComponent) {
nextComponent = performWork(nextComponent)
}
})
为了能利用好处理工作的 API,我们需要将渲染工作分解为多个增量单元。为了解决这个问题,React 重新实现了算法,从原来的依赖于内置堆栈的同步递归模型改为带有链表和指针的异步模型。就像 Andrew 写的那样 :
如果只依赖于内置的堆栈,那么它将会持续工作直到栈空,如果我们可以随意中断堆栈和手动操作堆栈帧,这样不是很好吗?这就是 React Fiber 的目的。Fiber 就是专门针对 React 组件重新实现的堆栈,你可以将单个 fiber 视作一个虚拟的堆栈帧。
递归遍历#
React 官方文档 描述了以前的递归过程 :
默认情况下,当递归一个 DOM 节点的子节点时,
React会同时迭代两个子列表,并在出现差异时生成一个改变。
每一个递归调用都会往栈中加入一个帧,这是同步执行的。我们就会有这样的组件树 :

递归的方式是非常直观的,但是正如我们所说的那样,它具有限制,最大的问题就是不能够拆分任务,不能够灵活地控制任务。因此 React 提出了新的单链表树遍历算法,使得暂停遍历和终止增长的堆栈成为可能。
链表遍历#
Sebastian Markbage 在这里 简略地描述了这个算法,为了实现这个算法,我们需要一个带有这三个属性的数据结构 :
- child : 指向第一个孩子节点
- sibling : 指向第一个兄弟节点
- return : 指向父节点
基于这样的数据结构我们就有了这样的组件结构 :
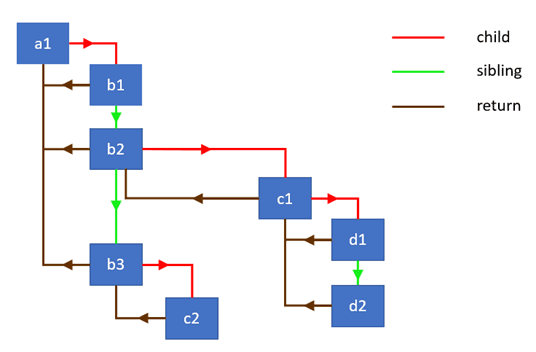
基于这样的结构我们就可以用自己的实现来替代浏览器的堆栈实现。
如果你想了解两种遍历详细的代码实现可以见 The how and why on React’s usage of linked list in Fiber to walk the component’s tree 。
最后让我们来看一下详细的 Fiber 节点结构,以 ClickCounter 和 span 为例 :
{
stateNode: new ClickCounter,
type: ClickCounter,
alternate: null,
key: null,
updateQueue: null,
memoizedState: { count: 0 },
pendingProps: {},
memoizedProps: {},
tag: 1,
effectTag: 0,
nextEffect: null
}
{
stateNode: new HTMLSpanElement,
type: "span",
alternate: null,
key: "2",
updateQueue: null,
memoizedState: null,
pendingProps: {children: 0},
memoizedProps: {children: 0},
tag: 5,
effectTag: 0,
nextEffect: null
}
alternate、effectTag 和 nextEffect 前文已经解释过,我们来看看其它属性 :
- stateNode : 指代类组件、DOM 节点或者其它与 fiber 节点相关的
React元素类型。 - type : 描述了这个 fiber 对应的组件。
- tag : 定义了 fiber 的类型,决定需要处理什么工作。(处理函数为createFiberFromTypeAndProps)
- updateQueue : 一个状态更新、回调函数以及 DOM 更新的队列。
- memoizedState : 用于创建输出 fiber 的状态。当更新时,它反映的是当前渲染在屏幕上的状态。
- pendingProps : 与之相对的是
memoizedProps,前者在开始执行时被设置,后者在结束时设置。如果传入的pendingProps等于memoizedProps,则表示这个 fiber 先前的输出可以复用,避免不必要的工作。 - key : 作为唯一标识符可以帮助
React确定哪些项被更改、添加或者移除。(可见lists and keys)
关于 Fiber 的运作过程,还有一个视频是非常值得去看的 : Lin Clark - A Cartoon Intro to Fiber - React Conf 2017 。
参考 :